Article - Publié le
Le pass Culture c’est plusieurs dizaines de devs, un trafic intense à toute heure du jour et de la nuit, des tables de base de données de plusieurs centaines de millions de lignes et une volonté forte de ne jamais afficher une page de maintenance à nos utilisateurs.
Ce contexte techniquement exigeant nous a forcé à régulièrement améliorer nos processus de mise en production. En période d’affluence notre base de données doit en effet gérer jusqu’à 6000 opérations par secondes.
Dans cet article nous détaillons comment nous faisons évoluer au quotidien nos schémas de base de données sans downtime.
Pour gérer nos changements de schéma de base de données, nous utilisons des migrations DDL (*Data Definition Language*) qui nous garantissent que notre schéma de base de données Postgresql est en cohérence avec nos modèles Python grâce au duo SQLAlchemy & Alembic.
Dans le cadre d’un service sans downtime, certaines migrations peuvent se révéler complexes.
Prenons un exemple: dans un modèle `User`, je souhaite supprimer un champ obligatoire (*non-nullable*) :

Intuitivement, on pourrait faire cela en 2 étapes :
- On supprime le champ du modèle ;
- On supprime la colonne via la migration générée.
class User(BaseModel):
id: int"""Remove obsolete_stuff column"""
from alembic import op
import sqlalchemy as sa
revision = "d3bd3af52558"
down_revision = "ca50ad3c3fd6"
def upgrade() -> None:
op.drop_column("user", "obsolete_stuff")
def downgrade() -> None:
op.add_column("user", sa.Column("obsolete_stuff", sa.VARCHAR(56))Mais lors du déploiement, on aurait alors une interruption de service car la base de données et le code du backend ne peuvent pas être déployés *exactement* au même instant.
Même si le délai entre les deux est très court, des utilisateurs seraient confrontés à une interruption de service.
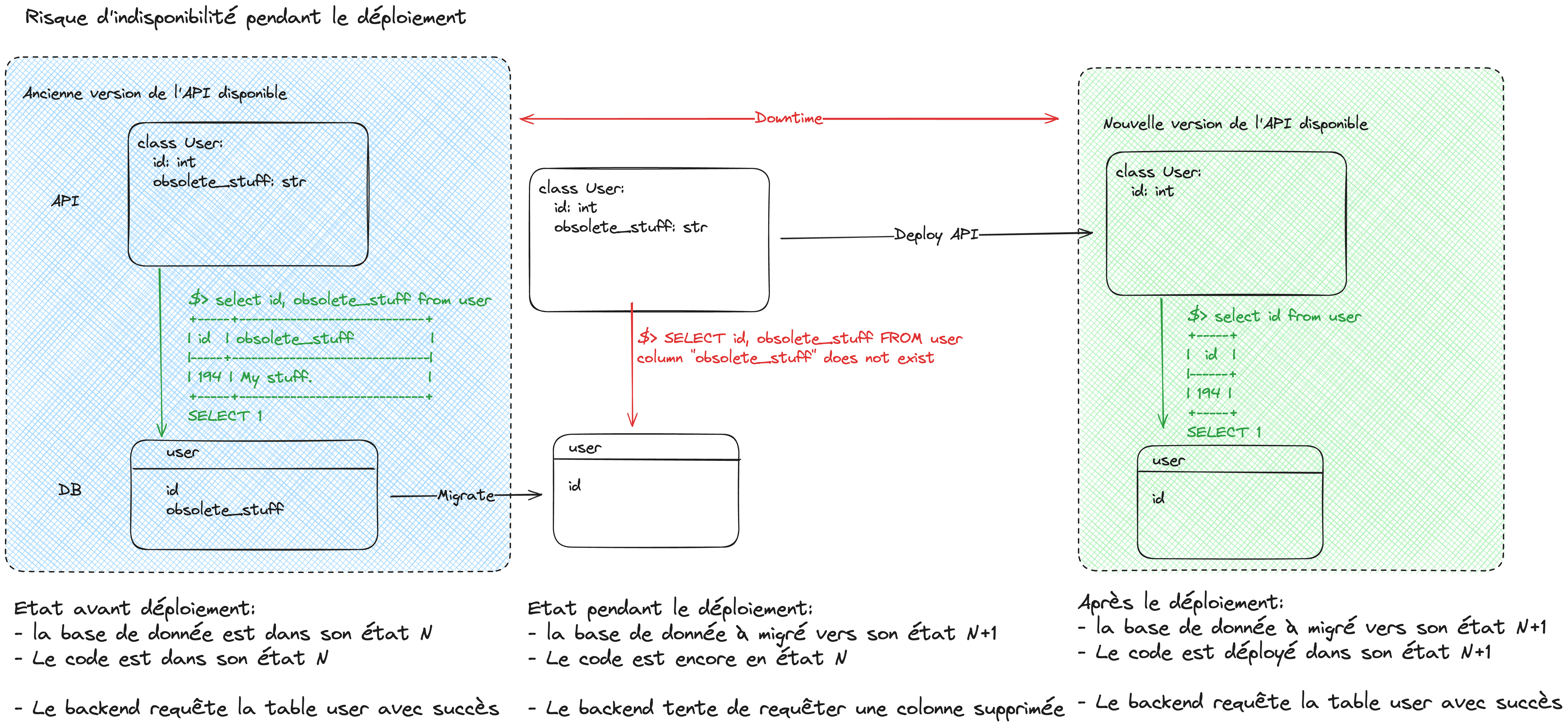
On doit donc procéder en plusieurs étapes, étalées sur deux déploiements distincts:
- Migration pour rendre la colonne *nullable*
- Modification du code applicatif pour supprimer les références à cette colonne
- Migration pour supprimer la colonne

On n’a alors pas d’interruption de service 🎉
Mais c’est un process compliqué donc propice aux erreurs, ce qui est bien sûr arrivé.
Alors comment améliorer ça ?
Pour réduire le nombre de déploiements pour une migration complexe, la solution fut de créer deux branches alembic, l’une étant exécutée avant le déploiement du code applicatif et l’autre après.
L’utilisation de deux branches permet d’appliquer les bonnes migrations au bon moment, en une seule mise en production. Comme leur nom l’indique, les migrations de la branche `pre` sont appliquées avant le déploiement du nouveau code, les migrations de la branche `post`, après.
La nouvelle solution, en un seul déploiement, est de :

Partant de la seule branche alembic que nous avions alors, nous avons créé deux migrations, non-successives partant de la même tête (exemple). À partir de cet instant, alembic considère qu’il a deux branches divergentes qui peuvent être utilisés indépendamment. Nous choisissons arbitrairement une de ces branches pour l’appliquer avant le déploiement et nous la renommons `pre`, l’autre branche s’appliquera après le déploiement et s’appellera `post`.
Comme décrit dans les schémas ci-dessus, une migration nécessaire au fonctionnement du code N+1 sera donc une migration `pre` (par exemple l’ajout d’une colonne nullable). Au contraire, une migration longue ou qui a besoin de la version N+1 du code, sera une migration `post` (rendre *non nullable* une colonne)
💡 Une autre utilité de la branche post est de permettre de faire passer des migrations longues après le déploiement. Si des migrations post-déploiement échouent, le code aura quand même été déployé. Les migrations en échec pourront être appliquées manuellement. Vue notre volumétrie, cette solution est très utilisée pour créer des indexes sur de très grosses tables (plusieurs dizaines de millions de lignes). La création d’index en mode non bloquant (voir la création d’index concurrents de postgreSQL), obligatoire vue la pression sur ces tables, peut prendre plusieurs heures et le job au sein d’une pipeline de déploiement atteindrait son timeout bien avant la fin de la création de l’index, qui serait alors invalide.
Nous vous avons présenté notre processus de déploiement sans maintenance. Il a été construit itérativement, au fil des erreurs et des besoins. Mais ce que nous vous avons présenté n’est qu’une partie de notre processus actuel, qui a continué à évoluer entre temps, et que nous vous présenterons dans un prochain article !
Article - Publié le